

A “commsversation” between Jeff Knezovich, Melissa Julian and the communications team at ECDPM
In the previous post, I suggested that the first step to taking communications activities to the next level is to get organised. This helps avoid the problem of ‘running before being able to walk’. To get organised, I suggested investing heavily in creating core lists.
In this blog post I hope to give a better idea of what these core lists start to look like by working through two different examples. One starts from the absolute back end, working to build related ‘spreadsheets’. The second works through a content management system (CMS) of sorts – namely a blogging platform.
As a warning, parts of this post are pretty technical, but never fear — next week we’re back to a more strategic discussion. Having said that, their aimed not at a developer (who probably knows this stuff anyway) but at more of a lay audience so that they understand the basics of what data structuring involves.
And one last note before we get started: these lists are almost never right the first time around. I could not more highly recommend an approach based on learning-by-doing and iterating from there – in the software development community, this is known as the agile methodology.
From Google Drive to IMAKE dream planner
Recently ECDPM moved from using one Google document listing upcoming communications products and one Google doc listing upcoming external events to an IMAKE-generated Google spreadsheet. The Google documents were easy to throw information into, but difficult to pull information out of to discuss with programme colleagues. Our new IMAKE system has allowed us to bring these two lists together into one place that we call our “Communications Planning Tool”. It is easier to put information in to and filter and pull information out of (by communications channel/tool, date, external event, programme, person, topic, etc.). Inputs are centralised via the Communications Manager, but the Google spreadsheet output is used by the entire centre.
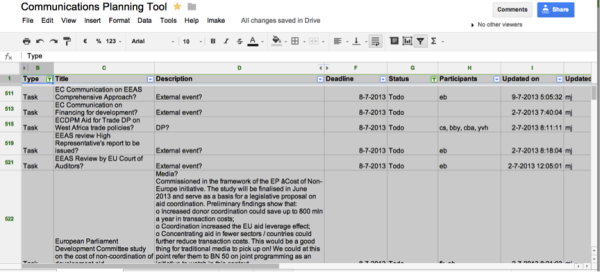
Building Core Lists with Google Drive
The first example I’ve put together using Google Drive’s ‘Spreadsheets’ app. But that was for easy sharing on the web. This could just as equally be done in Excel or a similar programme. In the long run, this could be used as the basis for an institutional website and/or an intranet, and it won’t likely remain in spreadsheet form. For those knowledgeable on how to setup databases, I’d recommend going straight to Microsoft Access, or indeed building a web-based version using MySQL, for example.
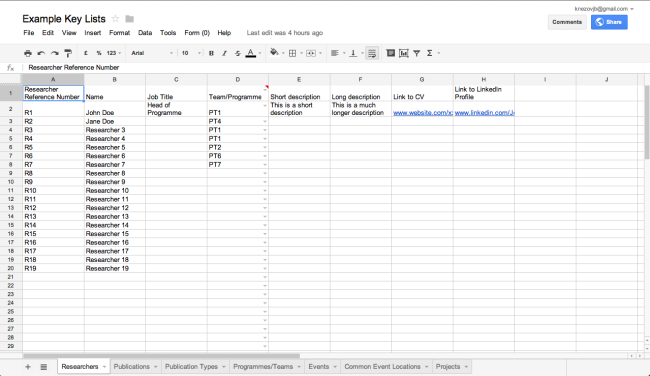 View a live version >> (opens in a new page)
View a live version >> (opens in a new page)
In this example, the first thing to note is that I’ve started by setting up a number of lists by creating multiple sheets within the document. The first one is called ‘Researchers’, while the second is called ‘Publications’. Each list will have at least one ‘anchor’ column (or ‘primary key’ in programming speak) that can only be modified from within that list, and that may be used as a reference to lookup information from that list in a different one. In the case of ‘Researchers’, both the ID and the Researcher Name (which you may want to split out into two fields: First Name and Last Name in practice) are anchor fields. In GoogleDrive, the way to more-or-less mimic this is in the Data menu, selecting ‘Named and Protected Ranges’. In this case I’ve setup the range ‘Researchers!B2:B30’ to be called ‘ResearchNames’. This is important for being able to use this information on another sheet or list. A similar process can be done in Excel.
Flipping to the ‘Publications sheet’, it becomes clearer why naming the range is important. In column F, ‘Institutional Author 1’, each cell has the option of a drop down list, from which it is possible to select a researcher’s name. I’ve done this in GoogleDocs by going to the Data menu, and selecting ‘Validation’ after having selected the cells from F2 to F22. In the validation options, under criteria select ‘Items from a list’. Ensure that the ‘Create list from cell range’ is selected, and in the text box input the named cell range – in this case ‘ResearchNames’. After hitting ‘save’, the dropdown box will appear once clicking into the cell. Clicking through the other sheets, one can find similar linkages.
This process may require some mindmapping or developing flow charts to help get an appropriate structure for all the content. I recommend digging around the lists I’ve made available in Google Drive for inspiration and then working through something similar for your own organisation. Once you start trying to populate the lists, you’ll quickly realise what sort of information is missing and add it in. In terms of populating the lists, I recommend starting with the most basic lists first – like names of researchers and continuing from there. It may also help to start adding more current publications before considering how older ones fit into the system.
I also recommend starting with ‘content-focused’ data first (e.g. adding in publication summaries). But as the lists develop, it is possible to add more process information – e.g. target publication dates (which we all know might ultimately be different from the actual dates) and yes/no tick boxes indicating different approvals/authorisations.
Building Core Lists on a blogging platform
When I worked at ODI, the core lists were built from the bottom up – mainly because some of the free online resources that exist today didn’t five years ago. But when I moved to Future Health Systems (FHS), I was confronted with a different scenario. I had a website that was still built using flat pages and HTML – it was a nightmare to update, and it was impossible to get an overview of what the consortium had already produced let alone gather data on what had worked and what hadn’t. I had the further challenge that the project funder no longer wanted to fund expensive websites. So I turned to SquareSpace, which is a blogging platform at its heart, to get me organised. But other projects I’ve worked with do the same things on other platforms, WordPress for an example of a blog platform, or Drupal as an example of a more content management driven platform.
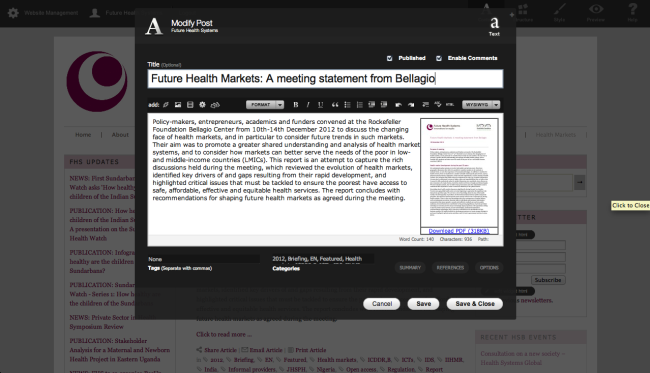
The key here is to start pushing the boundaries of understanding what a blog is. That begins to allow more flexibility in how to structure data. To create a publications database for FHS, I started a publications ‘blog’ on the site. Each publication I could find on the old site was given its own individual ‘blog’ post. The name of the post was the title of the publication. The content of the blog post relates to the ‘long description’ column in the Google Drive example above; there was also a place for a ‘summary’, which serves the same purpose as the ‘short description’ in the Publications spreadsheet.
The creative bit came with using ‘tags’, ‘themes’, and ‘authors’. To begin building the equivalent of the ‘researcher’ spreadsheet, most blog platforms allow one to setup different ‘users’ of the platform, who then become the ‘author’ of the post. The problem with this approach is that it means setting up a new website user for each author of every publication. That can get messy and time consuming, especially as the default author will likely be listed as the administrator. So instead, for the FHS publications ‘blog’ I chose to appropriate the ‘tags’ field for author names.
For the ‘themes’ field I put a number of different lists into one – the year of publication, the language of publication, the programme country and the programme partner as well as the publication type are all mixed together.
This effectively creates the database by using a more manageable front-end system. However, with hosted systems like SquareSpace or WordPress, it is effectively impossible to access the backend of this database. It is, however, possible on installations on individual servers. To turn this back into a spreadsheet, I had to create a workaround based on the RSS feeds automatically produced by the website. I simply re-aggregated the RSS feeds using Yahoo!Pipes and spit out the content in a comma-delimited format, which is easily transportable into Excel.
I’ve got a ‘spreadsheet’ – now what?!
If completing these three steps sounds like a lot of work, that’s because it is! But while it requires a bit of an initial investment, if done well, the payoffs in the end will be substantial.
After populating each of the lists, one is able to start to get a picture of what kind of content is already available within a programme or organisation. This will help to identify particular patterns in content. Perhaps one programme, for example, is a heavy publisher. Perhaps there are clear annual peaks and troughs in outputs that can be managed with a bit of forward planning, etc.
And in terms of the implementation, it will serve to organise internal processes as well as automate external engagement activities.
In the next blogs will look more at what to do with this information.